Monitoring en production : comment détecter et résoudre les incidents rapidement
Written by
Raphaël
1/6/2026
6
min de lecture
Le moment où une équipe découvre un incident n’est presque jamais le moment où le problème a commencé.
Dans beaucoup d’applications web et mobiles, les premiers signes apparaissent côté utilisateur: un écran qui charge trop longtemps, une action qui semble fonctionner puis échoue, une opération qu’il faut relancer une seconde fois. L’application tient encore debout, mais elle commence déjà à faire perdre du temps.
C’est ce décalage qui rend les incidents applicatifs si coûteux. Le sujet n’est pas seulement de savoir qu’une panne existe. Le vrai enjeu consiste à détecter une dégradation assez tôt pour comprendre ce qui se passe, qualifier la cause, puis corriger avant que l’usage ne se détériore davantage.
Points clés de l'article
No items found.
Détecter plus tôt ce que les utilisateurs subissent
Une application en production ne bascule pas toujours d’un état sain à un état indisponible. Entre les deux, il existe une zone plus floue, et souvent plus dangereuse. L’outil répond encore, les services ne sont pas totalement arrêtés, les tableaux de bord ne clignotent pas forcément en rouge. Pourtant, l’expérience réelle s’abîme.
Les symptômes les plus fréquents ressemblent à ceci :
temps de chargement qui s’allonge sur une action précise ;
écran figé après validation ;
action métier à répéter pour obtenir le résultat attendu ;
erreurs intermittentes qui ne touchent qu’une partie des utilisateurs ;
navigation possible, mais avec une sensation de lenteur continue.
Pour une équipe métier, ces signaux ne sont pas anecdotiques. Ils perturbent le travail, créent de la méfiance et poussent à contourner l’outil. Dans une application mobile métier, quelques secondes de plus sur une action répétée plusieurs dizaines de fois par jour finissent par peser lourd.
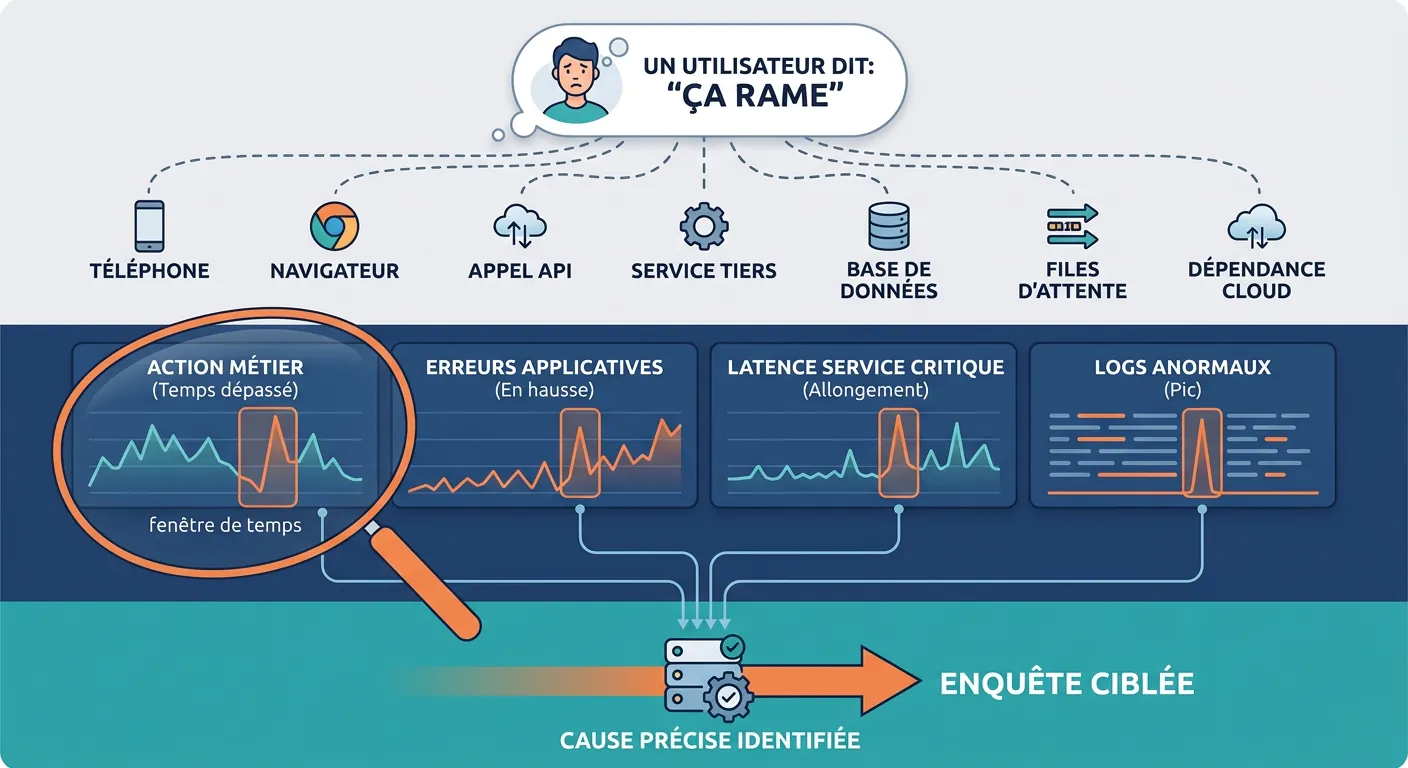
Relier plus vite le symptôme à la cause
Le vrai problème commence souvent quand une équipe sait qu’il y a une gêne, mais ne sait pas encore où regarder.
Un utilisateur dit que l’application « rame ». Cette information est utile, mais elle ne dit pas si l’origine du problème se situe côté frontend, backend, service tiers, base de données ou infrastructure cloud.
Pour raccourcir le diagnostic, il faut pouvoir relier plusieurs signaux sur une même fenêtre de temps : une action métier qui ralentit, une erreur applicative, une hausse de latence, un volume de logs inhabituel ou une ressource cloud sous tension.
Ce croisement change la manière d’analyser l’incident. L’équipe ne part plus dans cinq directions en parallèle. Elle dispose d’indices convergents pour formuler rapidement une hypothèse et intervenir sur le bon composant.
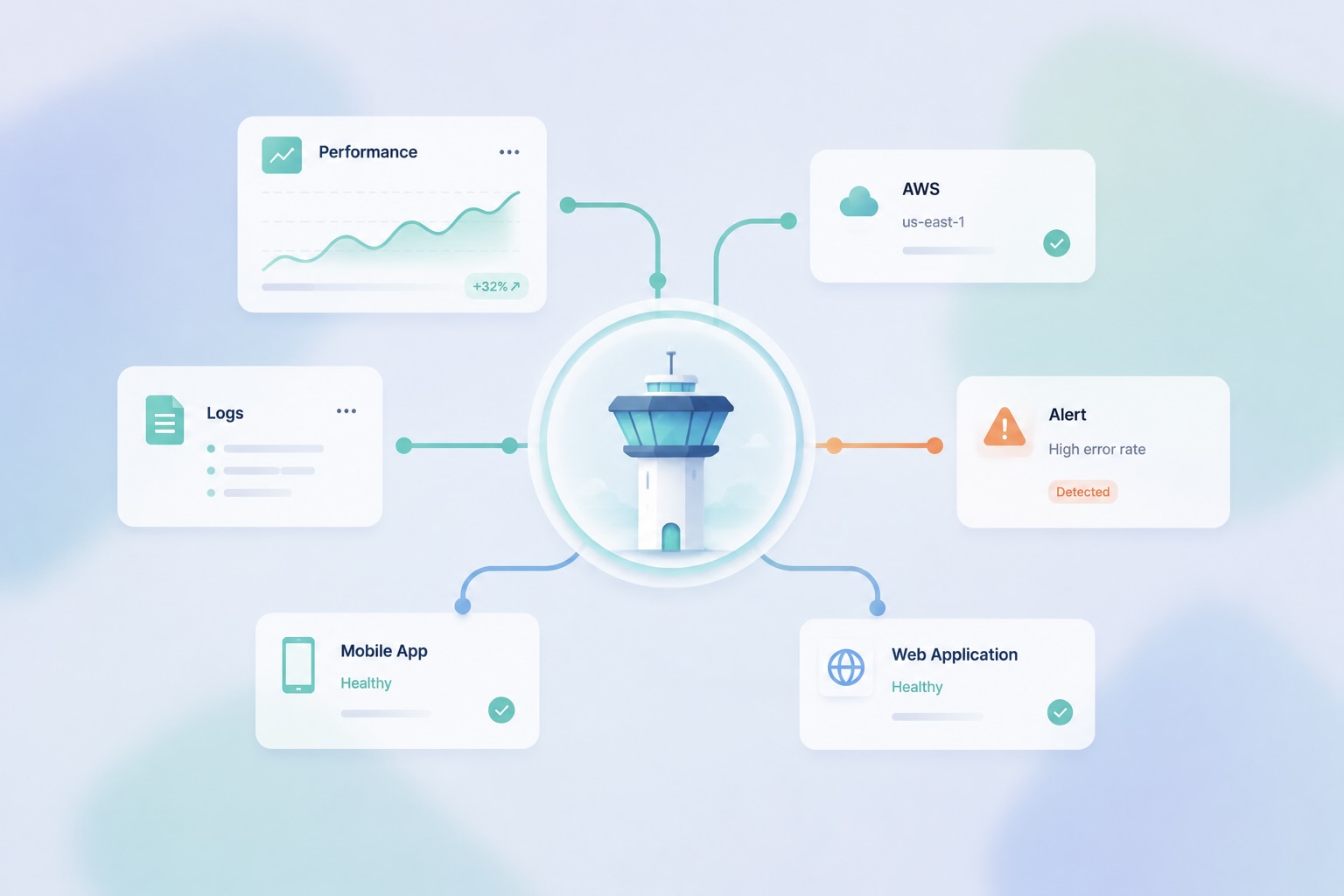
Le monitoring chez Nubios
Chez Nubios, le monitoring n’est pas une couche technique ajoutée après la mise en production. Il est pensé dès le départ pour aider les équipes à détecter plus tôt, comprendre plus vite et intervenir au bon endroit.
Concrètement, nous mettons en place une surveillance à plusieurs niveaux :
Grafana pour centraliser les métriques et construire des dashboards lisibles ;
Loki pour explorer les logs et les relier aux incidents observés ;
Sentry pour suivre les erreurs frontend, backend et mobile ;
AWS CloudWatch pour surveiller l’infrastructure cloud, les services et les ressources critiques.
L’objectif n’est pas d’empiler des outils. C’est de relier les signaux entre eux.
Lorsqu’une application se dégrade, l’équipe doit pouvoir voir rapidement si le problème vient d’un parcours utilisateur, d’un service backend, d’une erreur applicative, d’un pic de charge ou d’une ressource cloud.
Des alertes sont aussi configurées sur les indicateurs sensibles : temps de réponse, erreurs récurrentes, crashs mobiles, consommation anormale, indisponibilité d’un service, échec de synchronisation, etc.
Selon les projets, ces alertes peuvent remonter par e-mail, Slack, Teams ou tout autre canal utilisé par les équipes.
Le monitoring évolue ensuite avec l’application : les seuils sont ajustés, les dashboards enrichis et les incidents passés permettent d’améliorer les futurs diagnostics.
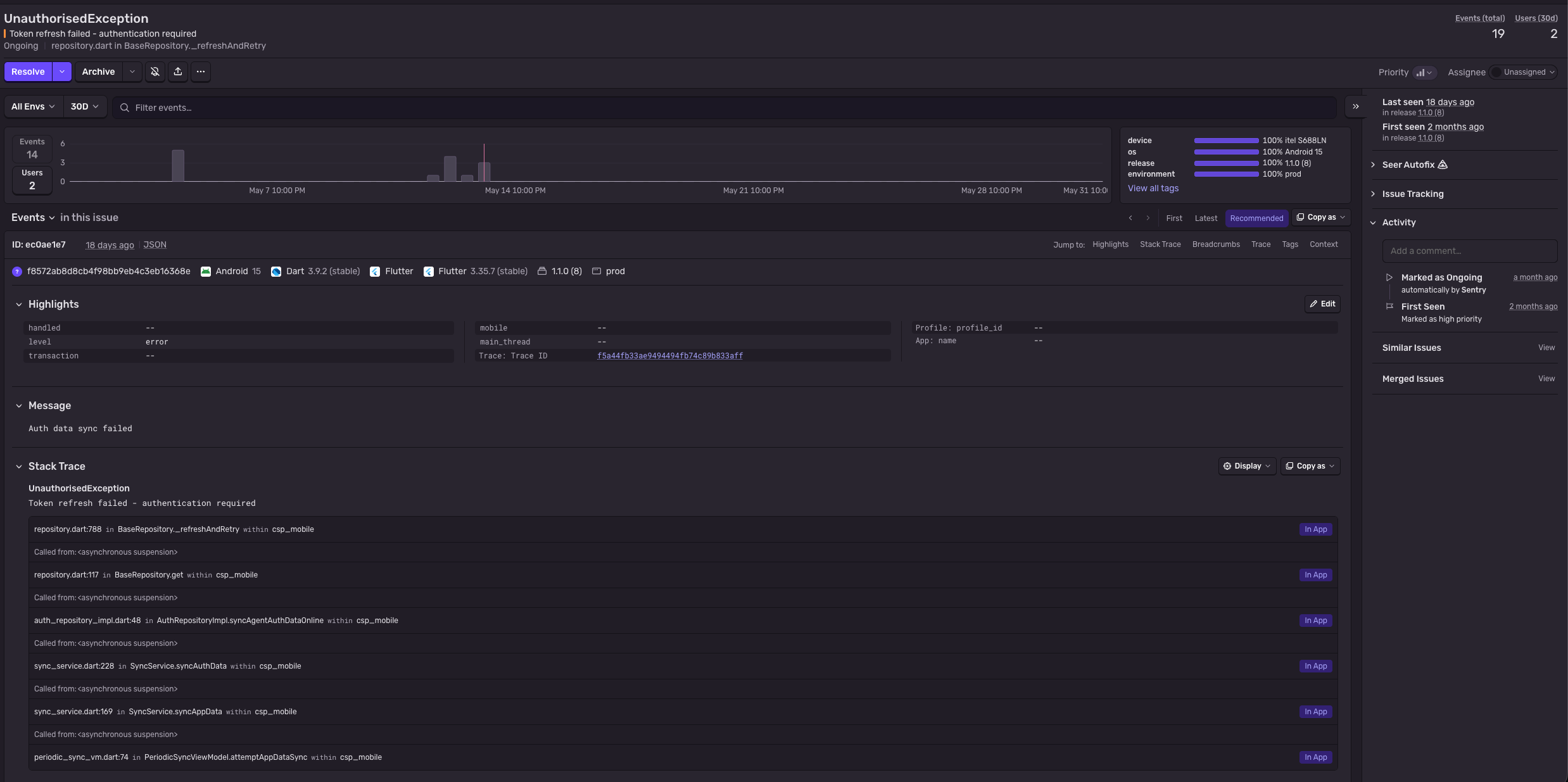
Détail d'une erreur remontée par Sentry
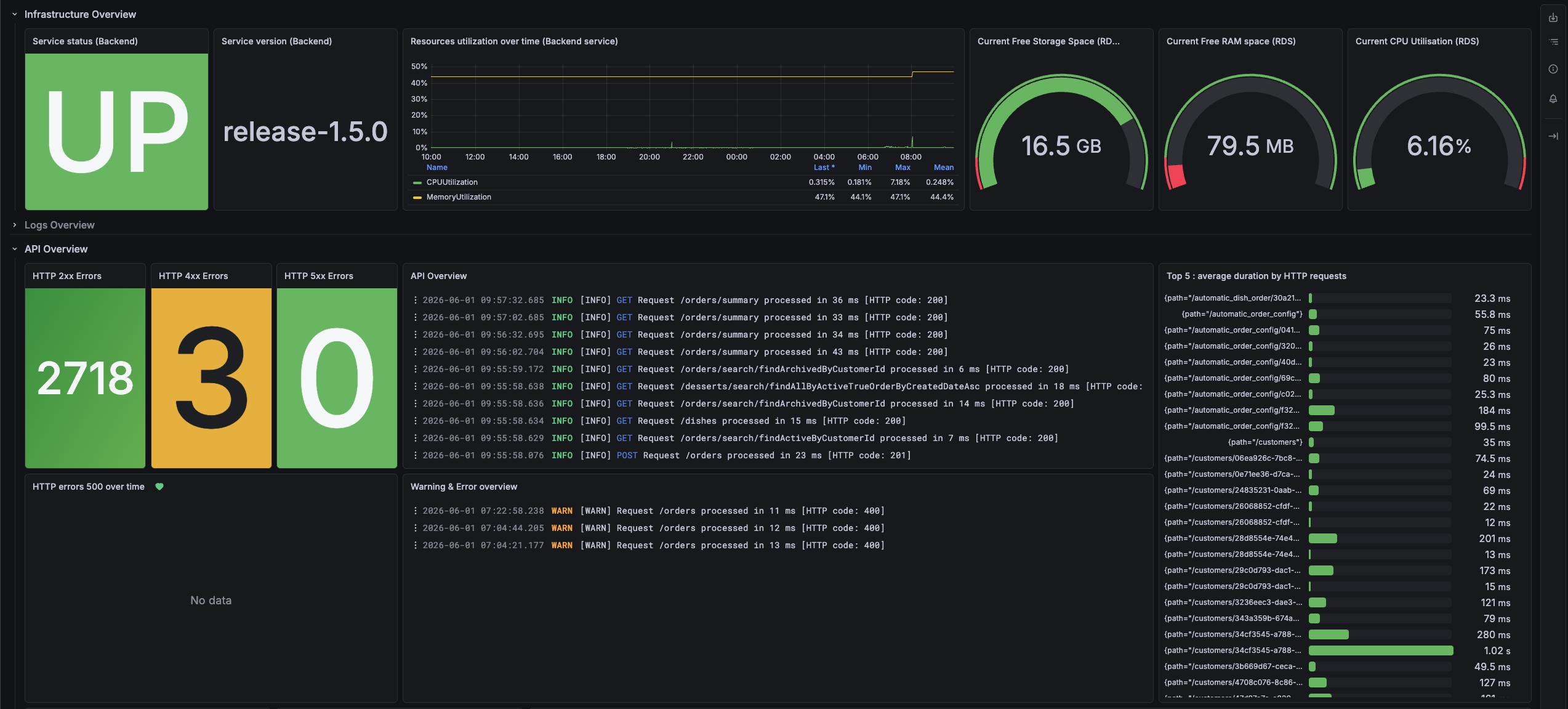
Ecran de l'état d'une application sur Grafana
Avez-vous des systèmes critiques non surveillés ?
Certaines applications sont devenues essentielles au quotidien : portail client, plateforme e-commerce, application métier, outil interne ou connecteur entre systèmes.
Mais savez-vous réellement quand elles commencent à se dégrader ?
Chez Nubios, nous aidons nos clients à identifier les points critiques, mettre en place les bons indicateurs et construire un monitoring utile, à la fois métier et technique.
Vous avez un doute sur la surveillance de vos applications critiques ? Parlons-en.
We use cookies to analyze the use of our website and to improve your experience. By accepting, you consent to the use of these cookies in accordance with our privacy policy.